
Seeing is not always believing—at least not for Ph.D. alumnus Ruohan Gao, whose research in machine learning uses senses beyond just sight to inform artificial intelligence.
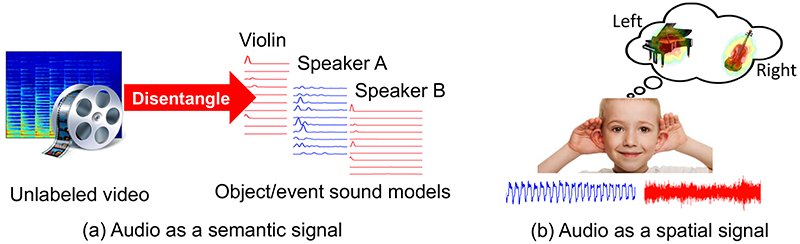
Gao’s work investigates how algorithms locate and understand audio-emitting objects when multiple sound sources are present. While conventional approaches to object identification in unsupervised machine learning rely solely upon visual cues, Gao’s work leverages audio as a semantic signal to disentangle object sounds in unlabeled video.
Gao’s dissertation “Look and Listen: From Semantic to Spatial Audio-Visual Perception” received the 2021 Michael H. Granof Award—the university’s top dissertation and graduate student award. Underwritten by the University Co-op, the Granof Award is named in honor of Dr. Michael H. Granof, former chair of the Co-op board and longtime professor at the university. The annual winner of the Granof Award receives a $6,000 prize.
His “Look and Listen” dissertation has become a leading work in the field. Gao’s work has already accumulated six top-tier publications, garnered three oral presentations and been selected as a Best Paper finalist at the most prestigious annual computer vision conference. This research plays a key role in scholarship on audio-visual deep learning; it has already amassed more than 380 academic citations thus far.
In his nomination letter for the Granof Award, Computer Science Professor Adam Klivans emphasized Gao’s innovative approach to problem-solving.
“His work is at the cutting-edge of perceptual computing, a key subfield within AI and Machine Learning,” said Klivans. “While we now have many machine learning systems for object recognition, they struggle with more sophisticated visual tasks. As an example, while we have powerful tools for detecting if a cat is in an image, we have almost no tools for describing what a cat is doing in an image or explaining its relationship to other objects. It is within this field of audio-visual understanding that Ruohan is a star.”
Gao recently took time out of his postdoctoral studies at Stanford University to answer questions about his research during his time at UT.

How would you explain the key findings of your dissertation to a non-specialist audience?
We humans perceive the world by both looking and listening (and touching, smelling, and tasting). While computer vision has made significant progress by “looking”— detecting objects, actions, or people based on their appearance—it often does not listen. In my dissertation, I find that if we open both our eyes and ears to perceive the world, things become much easier to understand because perceptions of the two modalities are mutually beneficial. Audio that accompanies visual scenes and events can tell us about object identities, their material properties, activities they are involved in, where they are in the 3-D space and more. Particularly, I have developed computational models that leverage both the semantic and spatial signals contained in audio to help us understand people, places and things from continuous multimodal observations.
What first attracted you to the field of AI and machine learning? How did you narrow your interest to audio-visual understanding?
I was attracted to the field of computer vision because of the ubiquitous and intuitive nature of visual data. Deep learning has revolutionized this field in the past decade. It was fascinating to see how a machine can quickly identify people and objects in an image. However, these successes almost all come from supervised learning and heavily rely on the emergence of large-scale datasets of millions of labeled examples. In contrast, babies learn by accumulating multi-modal experience (mainly through looking and listening) to understand the world without supervision from these manual labels. Thanks to the great guidance from my advisor Professor Kristen Grauman, I started to wonder how we can break free from the status quo of learning from bags of labeled snapshots through the creation of a system that learns “on its own” with minimal or no human supervision. I became interested in self-supervised learning, which exploits labels freely available in the structure of the data and uses them as supervision signals for visual learning. I analyzed tons of videos online and noticed that audio almost always accompanies visual frames. For example, if we hear a dog barking in the video, most likely there is also a dog lying visible in the frame. This led me to explore whether audio in unlabeled videos can be used as an abundant source of free supervision for visual learning.
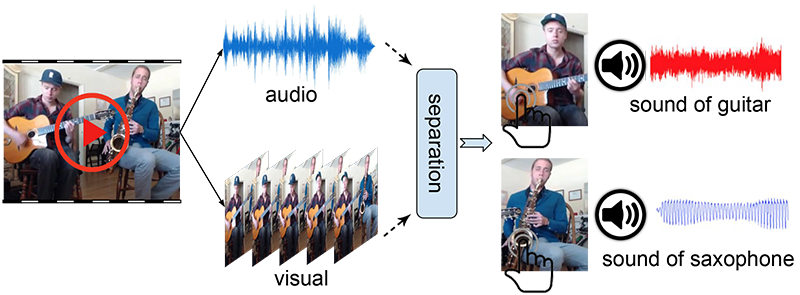
You developed a new method of audio-visual separation that uses a speaker's facial appearance as a cue to corresponding vocal qualities, rather than relying on alignment between the speaker’s lip movements and the sounds they generate. Could you please take me through this development process?
This problem is related to the famous cocktail-party effect. For decades, scientists have puzzled over how our brain is able to focus on certain sounds while filtering out others. This phenomenon is well illustrated by how someone at a party in a noisy room with many different sound signals around can easily focus on a single conversation. This distinguishment is possible because our brains formulate the problem as visually guided speech separation. Past approaches analyze the facial motion (lip movements) in concert with the emitted speech. Research has observed that the consistency between the speaker’s facial appearance and their voice is also revealing for speech separation. A person's gender, age, nationality and body weight are often visible in the face and give a prior for the voice qualities. Based on this understanding, we proposed to jointly learn audio-visual speech separation and cross-modal face-voice embeddings. The embeddings serve as a prior for the voice characteristics that enhance speech separation; the cleaner separated speech, in turn, produces more distinctive audio embeddings. We evaluated our model on audio-visual speech separation and achieved state-of-the-art results on standard benchmarks.
Were there any significant hurdles that arose during this project? Can you please share any creative solutions you came up with to overcome them?
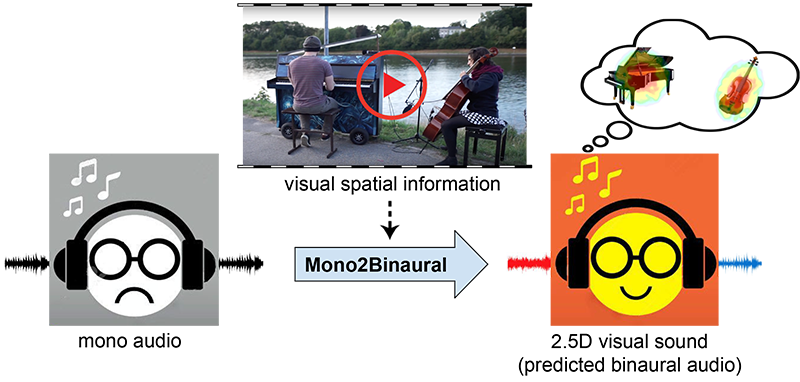
One major hurdle I encountered was in the 2.5D Visual Sound project. One day, I was watching some YouTube 360 videos with spatial audio when an idea came to my mind: Why can’t we have such spatial audio in normal everyday videos? We receive two-channel binaural audio to perceive spatial information, but spatial effects are absent in monaural audio. I had an idea to lift the single-channel monaural audio to a binaural level, which has both the left channel and the right channel, to mimic human hearing.
However, the scarcity of binaural recordings meant that we lacked the data to train such models. I got stuck for a long time trying to find the right data. After a lengthy exploration period, I decided to create a video dataset of binaural audios by myself. I assembled a data collection rig with a GoPro camera attached to a binaural microphone that mimics human hearing and records signals received in both ears separately. Using this dataset collection rig, I captured about five hours of video and binaural sound in a music room so we could finally have the data for this problem. It takes a lot of effort to create such a dataset, but the results are very rewarding.
How do you think an increased ability for learning from unlabeled video has changed or will change the field of AI/machine learning?
The future of Artificial Intelligence demands a paradigm shift towards unsupervised learning—with systems that can learn while autonomously exploring new environments, digest ongoing multi-sensory observations and discover structure in unlabeled data. An unsupervised or self-supervised approach to perform visual learning from unlabeled videos is much more scalable because unlabeled videos can be obtained essentially for free and are available in practically unlimited quantities. I believe unsupervised learning from unlabeled videos would play a positive and crucial role in the future progress of Artificial Intelligence.
What are you currently doing and what are your plans for the future?
I am currently doing a postdoc at Stanford University as I continue my research on learning from multisensory data. The long-term goal of my research is to build systems that can perceive and act as well as we do by combining all multisensory inputs.